
La data protection è il processo di salvaguardia di informazioni importanti da danneggiamento, compromissione o perdita.
L’importanza della data protection aumenta man mano che la quantità di dati creati e archiviati continua a crescere inoltre diminuisce la tolleranza per i tempi di inattività che possono rendere impossibile l’accesso a informazioni importanti.
Di conseguenza, gran parte di una strategia di data protection è garantire che i dati possano essere ripristinati rapidamente dopo qualsiasi danneggiamento o perdita. La protezione dei dati dalla compromissione e la garanzia della riservatezza dei dati sono altri componenti chiave della data protection.
Indice degli argomenti
Principi di data protection
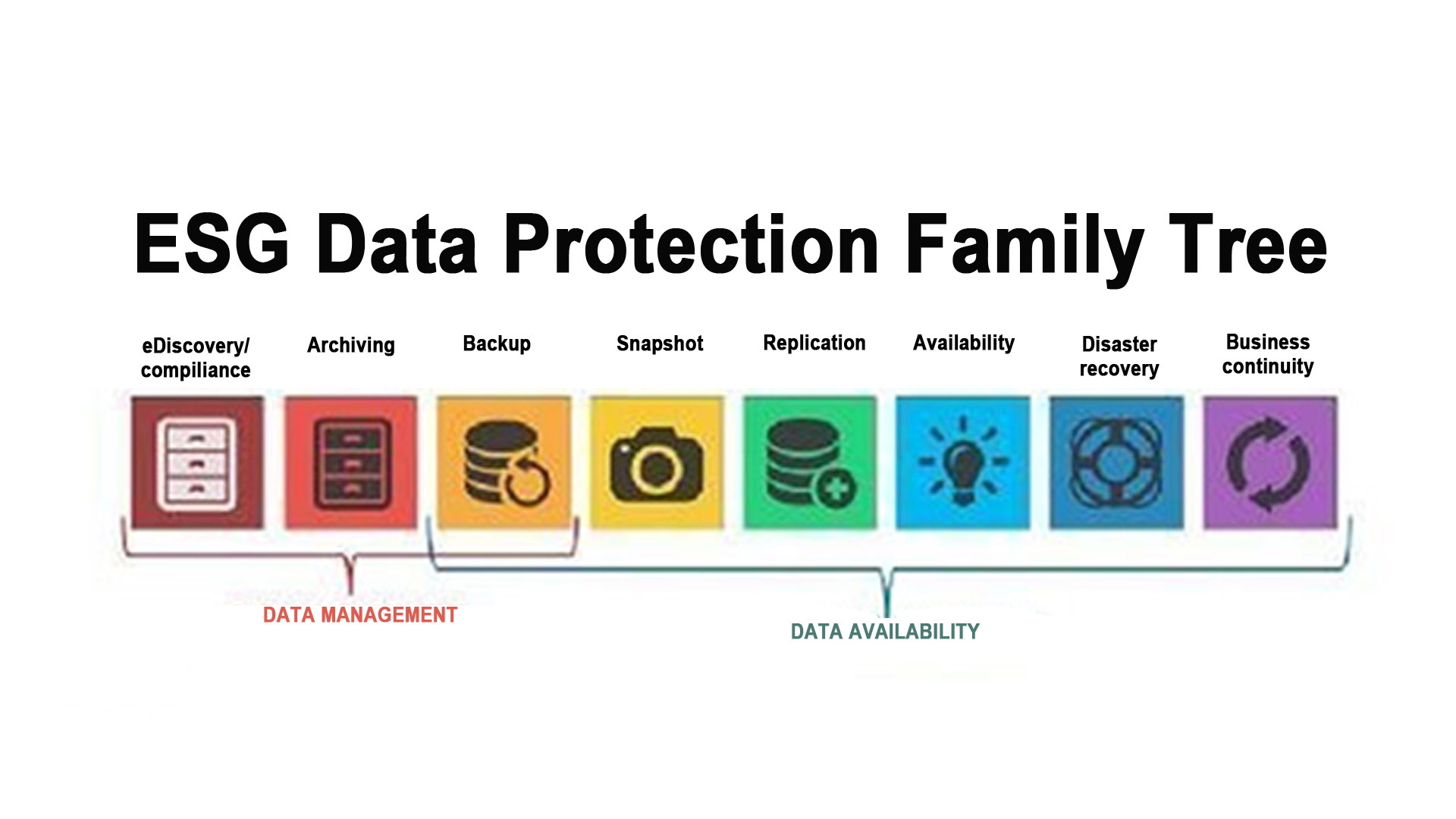
I principi chiave della data protection sono salvaguardare e rendere disponibili i dati in tutte le circostanze. Il termine data protection viene utilizzato per descrivere sia il backup operativo dei dati sia la continuità operativa / ripristino di emergenza (business continuity / disaster recovery). Le strategie di data protection si stanno evolvendo lungo due linee: disponibilità e gestione dei dati.
La disponibilità dei dati garantisce che gli utenti dispongano dei dati di cui hanno bisogno per condurre la propria attività anche se i dati vengono danneggiati o persi.
Esistono due aree chiave della gestione dei dati utilizzate nella data protection:
- gestione del ciclo di vita dei dati – è il processo di automazione del movimento di dati critici nello storage online e offline
- gestione del ciclo di vita delle informazioni – è una strategia completa per valutare, catalogare e proteggere le risorse informative da errori di applicazioni e utenti, attacchi di malware e virus, guasti delle macchine o interruzioni e interruzioni delle strutture.
Più recentemente, la gestione dei dati è arrivata a includere la ricerca di modi per sbloccare il valore aziendale da copie di dati altrimenti dormienti per la creazione di report, l’abilitazione di test / sviluppo, analisi e altri scopi (figura 1).
Qual è lo scopo della data protection?
Le tecnologie di archiviazione che possono essere utilizzate per proteggere i dati includono un backup su disco o nastro che copia le informazioni designate su un array di archiviazione basato su disco o su una cartuccia a nastro in modo che possano essere archiviate in modo sicuro. Il mirroring può essere utilizzato per creare una replica esatta di un sito Web o di file in modo che siano disponibili da più di un posto. Gli snapshot di archiviazione possono generare automaticamente una serie di puntatori alle informazioni archiviate su nastro o disco, consentendo un ripristino più rapido dei dati, mentre la protezione continua dei dati (CDP – Continuous Data Protection) esegue il backup di tutti i dati in un’azienda ogni volta che viene apportata una modifica.
Portabilità dei dati
La portabilità dei dati, ovvero la capacità di spostare i dati tra diversi programmi applicativi, ambienti informatici o servizi cloud, presenta un altro insieme di problemi e soluzioni per la data protection. Da un lato, il cloud computing consente ai clienti di migrare dati e applicazioni tra o tra fornitori di servizi cloud (CSP). D’altro canto, richiede salvaguardie contro la duplicazione dei dati.
In ogni caso, il backup nel cloud sta diventando sempre più diffuso. Le organizzazioni spostano spesso i dati di backup su cloud pubblici o cloud gestiti da fornitori di backup. Questi backup possono sostituire il disco in loco e le librerie a nastro oppure possono fungere da copie protette aggiuntive dei dati.
Il backup è stato tradizionalmente la chiave per una strategia di data protection efficace. I dati venivano copiati periodicamente, in genere ogni notte, su un’unità a nastro o una libreria a nastro dove sarebbero rimasti fino a quando qualcosa non andava storto con l’archiviazione dei dati primaria. In quel momento sarebbe possibile accedere ai dati di backup e utilizzarli per ripristinare i dati persi o danneggiati.
I backup non sono più una funzione autonoma, ma vengono combinati con altre funzioni di data protection per risparmiare spazio di archiviazione e ridurre i costi.
Il backup e l’archiviazione, ad esempio, sono stati trattati come due funzioni separate. Lo scopo del backup era ripristinare i dati dopo un errore, mentre un archivio forniva una copia dei dati ricercabile. Tuttavia, ciò ha portato a set di dati ridondanti. Oggi esistono prodotti che eseguono il backup, l’archiviazione e l’indicizzazione dei dati in un unico passaggio. Questo approccio fa risparmiare tempo alle organizzazioni e riduce la quantità di dati nell’archiviazione a lungo termine.
Il backup su cloud sta diventando sempre più diffuso. Le organizzazioni spostano spesso i dati di backup su cloud pubblici o cloud gestiti da fornitori di backup. Questi backup possono sostituire il disco in loco e le librerie di nastri oppure possono fungere da copie protette aggiuntive dei dati.
La convergenza tra disaster recoverye backup
Un’altra area in cui le tecnologie di data protection si stanno unendo è quella delle funzionalità di backup e disaster recovery (DR). La virtualizzazione ha svolto un ruolo importante qui, spostando l’attenzione dalla copia dei dati in un momento specifico alla protezione continua dei dati.
Storicamente, il backup dei dati ha riguardato la creazione di copie duplicate dei dati. Il ripristino di emergenza, d’altra parte, si è concentrato su come vengono utilizzati i backup una volta che si verifica un disastro.
Le snapshot e la replica hanno reso possibile il ripristino da un disastro molto più rapidamente rispetto al passato. Quando un server si guasta, i dati di un array di backup vengono utilizzati al posto dell’archiviazione primaria, ma solo se vengono intraprese misure per impedire che il backup venga modificato.
Questi passaggi prevedono l’utilizzo di un’istantanea dei dati dall’array di backup per creare immediatamente un disco differenze. I dati originali dell’array di backup vengono quindi utilizzati per le operazioni di lettura e le operazioni di scrittura vengono indirizzate al disco differenze. Questo approccio lascia invariati i dati di backup originali. E mentre tutto questo sta accadendo, lo storage del server guasto viene ricostruito e i dati replicati dall’array di backup allo storage appena ricostruito del server guasto. Una volta completata la replica, i contenuti del disco differenze vengono uniti alla memoria del server e gli utenti tornano al lavoro.
La deduplicazione dei dati gioca un ruolo chiave nel backup basato su disco eliminando le copie ridondanti dei dati per ridurre la capacità di archiviazione richiesta per i backup. La deduplicazione può essere incorporata nel software di backup o può essere una funzionalità abilitata per il software nelle librerie di dischi.
Le applicazioni di deduplicazione sostituiscono i blocchi di dati ridondanti con puntatori a copie di dati univoche. I backup successivi includono solo i blocchi di dati che sono cambiati dal backup precedente. La deduplicazione è nata come tecnologia di data protection e si è spostata nei dati primari come preziosa funzionalità chiave per ridurre la quantità di capacità richiesta per supporti flash più costosi.
La continuous data protection ha assunto un ruolo chiave nel disaster recovery e consente ripristini rapidi dei dati di backup. CDP consente alle organizzazioni di ripristinare l’ultima copia valida di un file o database, riducendo la quantità di informazioni perse in caso di danneggiamento o cancellazione dei dati. CDP è iniziato come una categoria di prodotti separata, ma si è evoluto fino al punto in cui è ora integrato nella maggior parte delle applicazioni di replica e backup. CDP può anche eliminare la necessità di conservare più copie dei dati. Invece, le organizzazioni conservano una singola copia che viene aggiornata continuamente man mano che si verificano modifiche.
Strategie di data protection aziendali
La moderna data protection per l’archiviazione primaria implica l’utilizzo di un sistema integrato che integra o sostituisce i backup e protegge dai seguenti potenziali problemi:
Errore del dispositivo di archiviazione
L’obiettivo qui è rendere disponibili i dati anche se un dispositivo di archiviazione non funziona.
Il mirroring sincrono è un approccio in cui i dati vengono scritti su un disco locale e un sito remoto contemporaneamente. La scrittura non è considerata completa fino a quando non viene inviata una conferma dal sito remoto, assicurando che i due siti siano sempre identici. Il mirroring richiede un overhead di capacità del 100%.
La protezione RAID è un’alternativa che richiede meno capacità di sovraccarico. Con RAID, le unità fisiche vengono combinate in un’unità logica che viene presentata come un singolo disco rigido al sistema operativo. RAID consente di archiviare gli stessi dati in luoghi diversi su più dischi. Di conseguenza, le operazioni di I/O si sovrappongono in modo equilibrato, migliorando le prestazioni e aumentando la protezione.
La protezione RAID deve calcolare la parità, una tecnica che controlla se i dati sono stati persi o sovrascritti quando vengono spostati da una posizione di archiviazione a un’altra, e tale calcolo consuma risorse di elaborazione.
Il costo del ripristino da un errore del supporto è il tempo necessario per tornare a uno stato protetto. I sistemi con mirroring possono tornare rapidamente a uno stato protetto. I sistemi RAID impiegano più tempo perché devono ricalcolare tutta la parità. I controller RAID avanzati non devono leggere un’intera unità per recuperare i dati durante la ricostruzione di un’unità; hanno solo bisogno di ricostruire i dati che si trovano su quell’unità. Dato che la maggior parte delle unità funziona a circa un terzo della capacità, il RAID intelligente può ridurre significativamente i tempi di ripristino.
La codifica di cancellazione è un’alternativa al RAID avanzato spesso utilizzato in ambienti di archiviazione con scalabilità orizzontale. Come il RAID, la codifica di cancellazione utilizza sistemi di data protection basati sulla parità, scrivendo sia i dati che la parità su un cluster di nodi di archiviazione. Con la codifica di cancellazione, tutti i nodi nel cluster di archiviazione possono partecipare alla sostituzione di un nodo guasto, quindi il processo di ricostruzione non viene limitato dalla CPU e avviene più velocemente di quanto potrebbe in un array RAID tradizionale.
La replica è un’altra alternativa di data protection per l’archiviazione con scalabilità orizzontale. I dati vengono rispecchiati da un nodo a un altro o su più nodi. La replica è più semplice della codifica di cancellazione, ma consuma almeno il doppio della capacità dei dati protetti.
Corruzione dei dati
Quando i dati vengono danneggiati o eliminati accidentalmente, è possibile utilizzare snapshot per sistemare le cose. La maggior parte dei sistemi di archiviazione odierni può tenere traccia di centinaia di snapshot senza alcun effetto significativo sulle prestazioni.
I sistemi di archiviazione che utilizzano gli snapshot possono funzionare con applicazioni chiave, come Oracle e Microsoft SQL Server, per acquisire una copia pulita dei dati durante l’esecuzione dello snapshot. Questo approccio consente snapshot frequenti che possono essere archiviate per lunghi periodi di tempo.
Quando i dati vengono danneggiati o vengono eliminati accidentalmente, è possibile montare un’istantanea e copiare i dati nel volume di produzione oppure l’istantanea può sostituire il volume esistente. Con questo metodo, i dati vengono persi minimi e il tempo di ripristino è quasi istantaneo.
Errore del sistema di archiviazione
Per proteggersi da più guasti alle unità o da altri eventi importanti, i data center si affidano a una tecnologia di replica basata sugli snapshot.
Con la replica snapshot, solo i blocchi di dati modificati vengono copiati dal sistema di archiviazione principale a un sistema di archiviazione secondario off-site. La replica snapshot viene utilizzata anche per replicare i dati nell’archivio secondario in loco che è disponibile per il ripristino in caso di guasto del sistema di archiviazione primario.
Errore completo del data center
La protezione contro la perdita di un data center richiede un piano completo di ripristino di emergenza. Come per gli altri scenari di errore, sono disponibili più opzioni. La replica snapshot, in cui i dati vengono replicati su un sito secondario, è un’opzione. Tuttavia, il costo di gestione di un sito secondario può essere proibitivo.
I servizi cloud sono un’altra alternativa. I prodotti e servizi di replica e backup su cloud possono essere utilizzati per archiviare le copie più recenti dei dati che potrebbero essere necessarie in caso di grave disastro e per creare istanze delle immagini dell’applicazione. Il risultato è un rapido ripristino in caso di perdita del data center.
Tendenze relative alla data protection
Le ultime tendenze nella politica e nella tecnologia di data protection includono quanto segue:
Iperconvergenza
Con l’avvento dell’iperconvergenza, i fornitori hanno iniziato a offrire appliance che forniscono backup e ripristino per ambienti fisici e virtuali iperconvergenti, non iperconvergenti e misti. Le funzionalità di data protection integrate nell’infrastruttura iperconvergente stanno sostituendo una gamma di dispositivi nel data center.
Cohesity, Rubrik e altri fornitori offrono iperconvergenza per lo storage secondario, fornendo backup, disaster recovery, archiviazione, gestione dei dati di copia e altre funzioni di storage non primarie. Questi prodotti integrano software e hardware e possono fungere da destinazione di backup per le applicazioni di backup esistenti nel data center. Possono anche utilizzare il cloud come destinazione e fornire backup per ambienti virtuali.
Ransomware
Questo tipo di malware, che tiene i dati in ostaggio per una tassa di estorsione, è un problema crescente. I metodi di backup tradizionali sono stati utilizzati per proteggere i dati dal ransomware. Tuttavia, il ransomware più sofisticato si sta adattando e aggirando i processi di backup tradizionali.
L’ultima versione del malware si infiltra lentamente nei dati di un’organizzazione nel tempo, quindi l’organizzazione finisce per eseguire il backup del virus ransomware insieme ai dati. Questa situazione rende difficile, se non impossibile, ripristinare una versione pulita dei dati.
Per contrastare questo problema, i fornitori stanno lavorando per adattare i prodotti e le metodologie di backup e ripristino per contrastare le nuove funzionalità del ransomware.
Gestione della copia dei dati
Il CDM (Copy Data Management) riduce il numero di copie di dati che un’organizzazione deve salvare, riducendo il sovraccarico necessario per archiviare e gestire i dati e semplificando la data protection. CDM può accelerare i cicli di rilascio delle applicazioni, aumentare la produttività e ridurre i costi amministrativi attraverso l’automazione e il controllo centralizzato.
Il prossimo passo con CDM è aggiungere più intelligenza. Aziende come Veritas Technologies stanno combinando CDM con le loro piattaforme di gestione dei dati intelligenti.
Disaster recovery as a service
L’uso di DRaaS è in espansione poiché vengono offerte più opzioni e i prezzi scendono. Viene utilizzato per i sistemi aziendali critici in cui viene replicata una quantità crescente di dati anziché solo backup.
Mobile data protection
La data protection sui dispositivi mobili ha le sue sfide. Può essere difficile estrarre i dati da questi dispositivi e la connettività incoerente rende difficile, se non impossibile, la pianificazione dei backup. La mobile data protection è ulteriormente complicata dalla necessità di mantenere i dati personali archiviati sui dispositivi mobili separati dai dati aziendali.
La sincronizzazione e la condivisione selettiva dei file è un approccio alla data protection sui dispositivi mobili. Sebbene non sia un vero backup, i prodotti di sincronizzazione e condivisione di file in genere utilizzano la replica per sincronizzare i file degli utenti in un repository nel cloud pubblico o sulla rete di un’organizzazione. È quindi necessario eseguire il backup di tale posizione. La sincronizzazione e la condivisione dei file consentono agli utenti di accedere ai dati di cui hanno bisogno da un dispositivo mobile, sincronizzando al contempo eventuali modifiche apportate ai dati con la copia originale. Tuttavia, non protegge lo stato del dispositivo mobile, necessario per un rapido ripristino.
Differenze tra sicurezza e privacy
In generale, la sicurezza dei dati si riferisce specificamente alle misure adottate per proteggere l’integrità dei dati stessi dalla manipolazione e dal malware, mentre la privacy si riferisce al controllo dell’accesso ai dati. Comprensibilmente, una violazione della privacy può portare a problemi di sicurezza dei dati.
Data protection e privacy
Le leggi e i regolamenti sulla privacy dei dati variano da paese a paese e persino da stato a stato, e c’è un flusso costante di nuovi. La legge cinese sulla privacy dei dati è entrata in vigore il 1 giugno 2017. Il regolamento generale sulla data protection (GDPR) dell’Unione europea è entrato in vigore nel 2018. La conformità a qualsiasi serie di regole è complicata e impegnativa.
Il coordinamento tra tutte le regole e i regolamenti disparati è un compito enorme. Essere inadempienti può comportare multe salate e altre sanzioni, incluso il dover smettere di fare affari nel paese o nella regione coperti dalla legge o dai regolamenti.
Per un’organizzazione globale, gli esperti consigliano di disporre di una politica di data protection che sia conforme al set di regole più rigorose che l’azienda deve affrontare, mentre, allo stesso tempo, utilizza un framework di sicurezza e conformità che copre un’ampia serie di requisiti. Le basi della data protection e della privacy si applicano su tutta la linea e includono:
- salvaguardia dei dati;
- ottenere il consenso dalla persona i cui dati vengono raccolti;
- identificare le normative che si applicano all’organizzazione in questione e i dati che raccoglie; e
- garantire che i dipendenti siano completamente formati sulle sfumature della privacy e della sicurezza dei dati.
Direttiva UE sulla data protection
L’Unione Europea ha aggiornato le sue leggi sulla privacy dei dati con una direttiva che è entrata in vigore il 25 maggio 2018. Il GDPR sostituisce la Direttiva sulla data protection dell’UE del 1995 e si concentra sul rendere le aziende più trasparenti. Espande inoltre i diritti alla privacy rispetto ai dati personali.
Il GDPR copre tutti i dati dei cittadini dell’UE indipendentemente da dove si trova l’organizzazione che raccoglie i dati. Si applica anche a tutte le persone i cui dati sono conservati all’interno dell’Unione Europea, siano essi cittadini dell’UE o meno.
I requisiti del GDPR includono:
- Impedire alle aziende di archiviare o utilizzare le informazioni di identificazione personale di una persona senza il consenso esplicito di tale persona.
- Richiedere alle aziende di informare tutte le persone interessate e l’autorità di controllo entro 72 ore da una violazione dei dati.
- Per le aziende che elaborano o monitorano i dati su larga scala, disporre di un responsabile della data protection responsabile della governance dei dati e garantire la conformità dell’azienda al GDPR.
Le multe per mancato rispetto possono arrivare fino a 20 milioni di euro o al 4% del fatturato mondiale dell’anno fiscale precedente, a seconda di quale sia il maggiore.







Partecipa alla community