
- Il mercato dell’analytics in Italia è in crescita e offre molte opportunità per le aziende che vogliono investire in questa tecnologia.
- I trend principali includono real-time analytics, machine learning, augmented analytics, self-service data analytics, data as a service e data monetization, insight platform e metodo Agile.
- Le applicazioni dell’analytics sono molteplici, tra cui web analytics, marketing optimization, people analytics, portfolio analytics, risk analytics, security analytics, ITSM analytics, manutenzione preventiva e software analytics.
Per chi ama la propria lingua è spesso irritante assistere all’utilizzo indiscriminato dell’inglese. È pur vero che, soprattutto in ambito tecnologico, la lingua inglese produce neologismi più rapidamente dell’italiano. E soprattutto si tratta di termini condivisi a livello globale. Per cui in alcuni casi è indispensabile farne uso. Data analytics, la cui traduzione in italiano, come faremmo per data analysis, è “analisi dei dati”, ne è un esempio eclatante. Data analytics ha, infatti, una traduzione ben precisa molto diversa dalla data analysis.
Indice degli argomenti
Il significato di analytics
Analytics è il processo scientifico di scoperta e comunicazione dei modelli significativi che possono essere trovati nei dati. In pratica i dati grezzi vengo trasformati in insights (intuizioni) utili per prendere decisioni migliori. Essa si basa su un insieme di scienze, tecniche e tecnologie che vanno dalla statistica, alla matematica, alle tecnologie di business intelligence di base, al reporting, all’elaborazione analitica online (Olap) e varie forme di analisi avanzate.

Questa definizione in sé non dice molto. Per una più precisa comprensione del significato di analytics è di aiuto vedere la differenza rispetto ad altre discipline, come analysis o business intelligence. È interessante poi capire da quando l’analytics ha iniziato a “staccarsi” dalle tradizionali tecniche di analisi dei dati per trasformarsi in un argomento a sé stante, ossia con la comparsa dei big data.
Analytics o analysis?
La differenza tra questi due termini è semplice e chiara. L’analysis è focalizzata sulla comprensione del passato, quello che è successo. Analytics si concentra sul perché è successo e su cosa succederà dopo.
Quali sono le differenze tra analytics e business intelligence
Più articolata è la differenza tra analytics e business intelligence.
La differenza principale tra le due sta nel concetto di modellazione insito nella prima, ma questa necessità di sviluppare modelli non si sarebbe manifestata se non si fosse consolidato (grazie alla digitalizzazione pervasiva e alla crescente disponibilità di dati) il fenomeno dei big data. Ecco perché analytics – modelli – big data sono 3 termini indissolubilmente legati tra loro.
È infatti l’evoluzione dei big data che ci aiuta ancor di più a capire le differenze tra analytics e business intelligence.
- La business intelligence utilizza la statistica descrittiva con dati ad alta densità di informazione per misurare cose, rilevare tendenze eccetera. Utilizza cioè dataset limitati, dati puliti e modelli semplici per scoprire cosa è successo e perché è successo. Grazie alla business intelligence sono state affinate le tecniche ETL ossia di estrazione, trasformazione e caricamento dei dati in un data warehouse.
- L’analytics utilizza la statistica inferenziale e concetti di identificazione di sistemi non lineari per dedurre modelli e per rivelare rapporti e dipendenze ed effettuare previsioni di risultati e comportamenti. Utilizza dataset eterogenei (non correlati tra loro), dati grezzi e modelli predittivi complessi.
La business intelligence è superata?
Non bisogna però pensare che la business intelligence sia non solo un termine obsoleto, ma anche un insieme di tecniche superate. L’analytics, per essere efficace, ha anche bisogno di tecniche di business intelligence più tradizionali per garantire la qualità del dato. Quello della qualità del dato è un concetto che vale sempre e comunque. Senza dati di qualità non c’è analytics o analysis o business intelligence che possa essere efficace, quindi i concetti di Data Quality e Data Governance sono quanto mai fondamentali.
Cosa sono i big data
Non fa male a questo punto un piccolo ripassino di cosa significa big data. Oggi è possibile raccogliere un’innumerevole quantità di dati, come conseguenza di Internet, dell’Internet of Things, dell’industrial Internet of Things e della diffusione della cosiddetta app economy.
I dati che vengono prodotti sono molteplici, come per esempio i dati degli utenti di un sito web, dei loro post Facebook, o dell’utilizzo di un’app eccetera.
Le 3 V del Big Data: ecco cosa sono
Ma non si tratta “semplicemente” di quantità enormi e di tipologia differente, quello della disponibilità e del loro cambiamento in tempo reale è un altro elemento che caratterizza i big data. Ecco perché li si è definiti con il modello di crescita tridimensionale delle 3 V definito nel 2001 dall’analista Douglas Laney.
Volume
Si partla di quantità di dati generati ogni secondo da sorgenti eterogenee quali: sensori, log, eventi, email, social media e database tradizionali.
Varietà
Si intende la tipologia differente dei dati che vengono generati, collezionati e utilizzati. Prima dell’epoca dei big data si tendeva a prendere in considerazione per le analisi principalmente dati strutturati e la loro manipolazione veniva eseguita mediante uso di database relazionali. Per avere analisi più accurate e più profonde, oggi è necessario prendere in considerazione anche dati non strutturati (file di testo generati dalle macchine industriali o i log di web server o dei firewall eccetera) e semi strutturati (per esempio, atto notarile con frasi fisse e frasi variabili) oltre che quelli strutturati (come la tabella di un database).
Velocità
Si riferisce alla velocità con cui i nuovi dati vengono generati. Si tratta non solo della celerità nella generazione dei dati, ma anche della necessità che questi dati/informazioni arrivino in tempo reale al fine di effettuare analisi su di essi. È fondamentalmente da questa caratteristica, che introduce il concetto di streaming, che si arriverà a pensare alla costruzione di data lake a fianco o al posto dei tradizionali data warehouse. Ma su questo torneremo poco più avanti.
La 4° e la 5° V
Con il tempo, sono state introdotte una quarta V, quella di veridicità, e poi una quinta, quella di Valore.
Veridicità
Come scrivevo poco sopra, quello della qualità del dato è un concetto basilare per analisi efficaci. Diciamo che nei primi anni di comparsa dei big data, molte aziende si sono talmente entusiasmate dalla quantità e varietà dei dati disponibili, da finire con il prestare minore attenzione a questo aspetto. Salvo poi trovarsi con dati talmente inquinati da rendere qualsiasi analisi non solo inattendibile, ma addirittura pericolosa. Ecco quindi che ci si è resi rapidamente conto che la “veridicità” doveva essere considerata una caratteristica intrinseca del dato da inserire nel processo di analisi.
Valore
Ci si riferisce alla capacità di trasformare i dati in valore. Anche questo è un concetto, di per sé ovvio e che è alla base della nascita stessa della business intelligence, sul quale è stato necessario rimettere l’accento proprio perché la grande abbuffata dei big data lo aveva fatto perdere un po’ di vista. La qualità di un dato, oltre ad alcuni elementi oggettivi, implica un problema concettuale, che se non attentamente affrontato inquina i risultati di ogni analisi. Si tratta della concettualizzazione di business che sta dietro a un qualsiasi progetto di analytics. Bisogna definire con chiarezza, in stretta relazione con il business owner del processo che genererà un determinato dato, quali sono gli elementi che caratterizzano il dato stesso.
È così che l’analytics porterà poi veramente valore di business e che questo valore sarà misurabile. Per esempio: in un progetto di loyalty possono esserci molte ambiguità nella definizione di cliente infedele. Se non si conosce bene il processo di business, se non si definisce con precisione cosa caratterizza il cliente infedele, l’analisi che ne deriverà non potrà essere corretta.

Data Warehouse e Data Lake: definizione e differenze
Ma dove stanno in azienda i dati? La domanda ci introduce ad altri due termini, Data Warehouse e Data Lake, sui quali è necessario fare un minimo di chiarezza. E questo, soprattutto, per non incorrere nel tipico, e superficiale, approccio che dichiara morte certe tecnologie perché non rispondono pienamente alle esigenze della “trasformazione digitale”. E penso ai mainframe, agli ERP eccetera. La facilità con cui, a volte anche per esigenze di marketing, si definiscono “rock” certe tecnologie induce a pensare che le “altre” debbano essere rapidamente dismesse.
Il Data Warehouse secondo alcuni dovrebbe seguire la sorte di cui sopra. In realtà non solo la sua costruzione è frutto di investimenti ingenti, ma per alcuni tipi di analisi svolge benissimo la propria funzione. Quindi si vanno sempre più spesso definendo architetture ibride che vedono i più tradizionali Data Warehouse affiancarsi ai più smart Data Lake.
Il conio del termine Data Lake è del 2010 ed è da attribuire a James Dixon, CTO di Pentaho (società di BI poi acquisita da Hitachi Data Systems), che utilizzò la metafora dell’acqua (i dati) e del lago o della bottiglia (bacino e contenitore) per esemplificare il concetto.
Data Warehouse
L’acqua, i dati, vengono imbottigliati in contenitori diversi a seconda del tipo di fonte che li ha generati e della destinazione e dell’uso. I dati vengono quindi salvati in formati omogeni, raffinati e pronti per essere distribuiti a operatori e sistemi con funzioni specifiche.
Il processo ETL è tipico dei Data Warehouse, alla base del cosiddetto “schema on write” dove viene definita a priori la struttura del database. I dati vengono scritti in questa struttura definita e quindi analizzati. Il processo è complesso e costoso dovendo tener conto delle future integrazioni e implementazioni con nuove sorgenti, fondamentale se non si vuole costruire un contenitore rapidamente obsoleto.
Le sue caratteristiche e modalità di accesso sono perfette per utenti che hanno bisogno di analisi abbastanza semplici e, soprattutto, che sanno cosa cercare, quale tipo di relazione analizzare. Sono utenti di business che trovano in questi “contenitori” e nei sistemi di business intelligence che li interrogano ottime risposte in termini di reportistica e per capire l’andamento di fenomeni conosciuti. E infatti le evoluzioni di queste soluzioni, nella prima decade degli anni 2000, erano concentrate sull’interfaccia utente e sulla possibilità di costruire dashboard per analisi di specifico interesse.
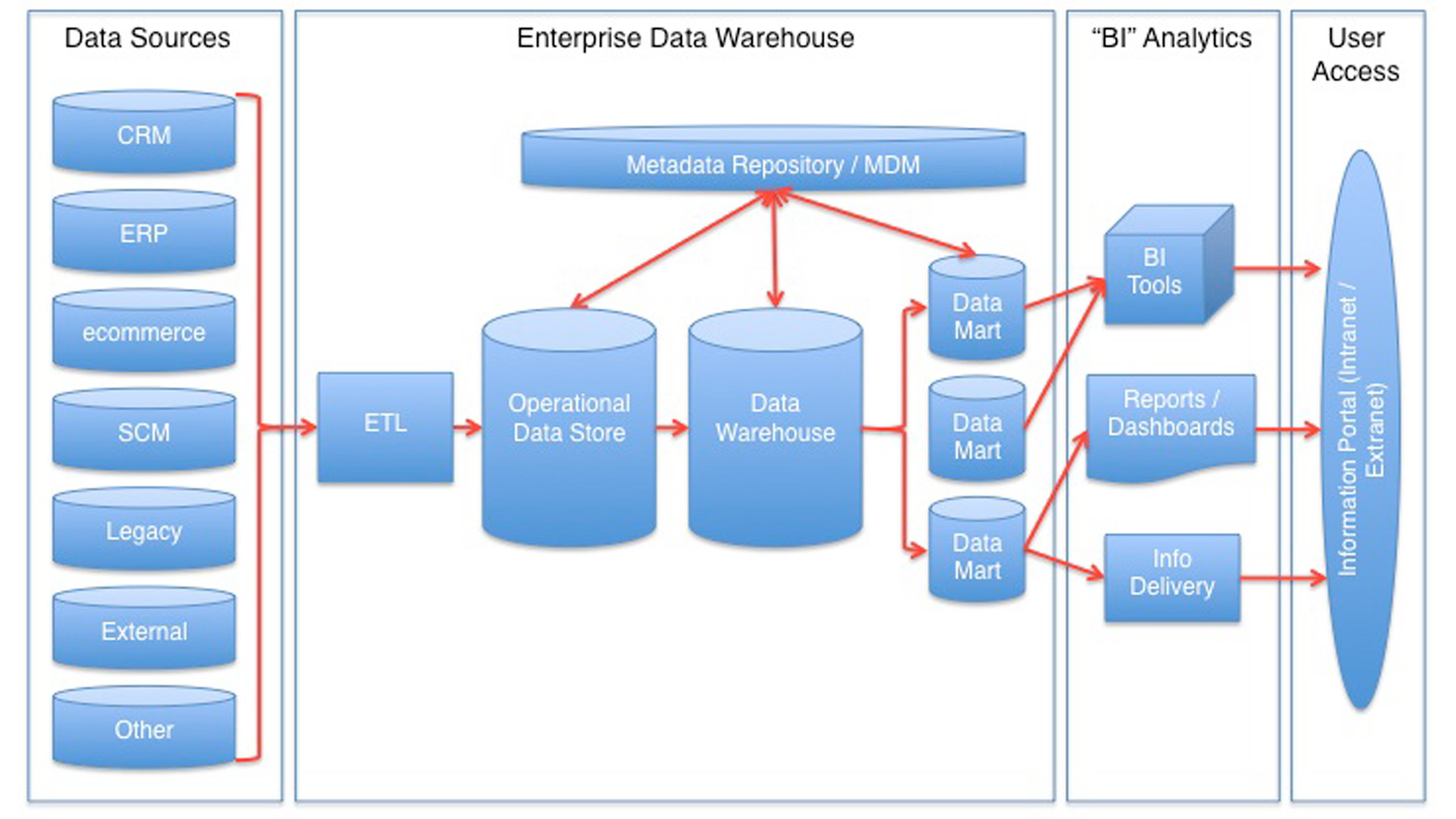
Fonte: DataZoomers
Data Lake
I dati, come l’acqua, fluiscono in questi “bacini” liberamente dalle fonti che li generano e in questi bacini vengono esaminati e campionati nei loro formati originari. Solo nel momento in cui vengono interrogati da applicazioni e operatori vengono convertiti in formati leggibili dai sistemi aziendali e quindi possono essere confrontati con altre informazioni.
Un Data Lake può includere dati strutturati da database relazionali (righe e colonne), dati semi-strutturati (CSV, log, XML, JSON), dati non strutturati (e-mail, documenti, PDF) e dati binari (immagini, audio, video).
Ogni elemento viene identificato in modo univoco attraverso una serie di tag che corrispondono ai suoi metadati. Questo consente, nel momento in cui un Data Lake viene interrogato relativamente a un problema specifico, di estrarre i dati rilevanti e quindi sottoporli ad analisi. È il cosiddetto “schema on read” dove i dati vengono letti senza dover essere “scritti” secondo uno specifico modello.
Il Data Lake, rispetto al Data Warehouse, ha il vantaggio di essere molto duttile e non richiedere lunghi tempi di implementazione. Ha una gestione più semplice ed è reversibile senza problemi (tipologie differenti di dati possono essere inserite e/o cancellate senza dover applicare modifiche alla struttura).
I Data Lake sono l’ideale per effettuare analisi sempre più profonde, scoprire relazioni inimmaginabili che possono portare all’identificazione di nuovi business, ma che necessitano di figure specializzate nell’analisi, tra cui primeggiano i Data Scientist, ma delle quali c’è grande carenza.
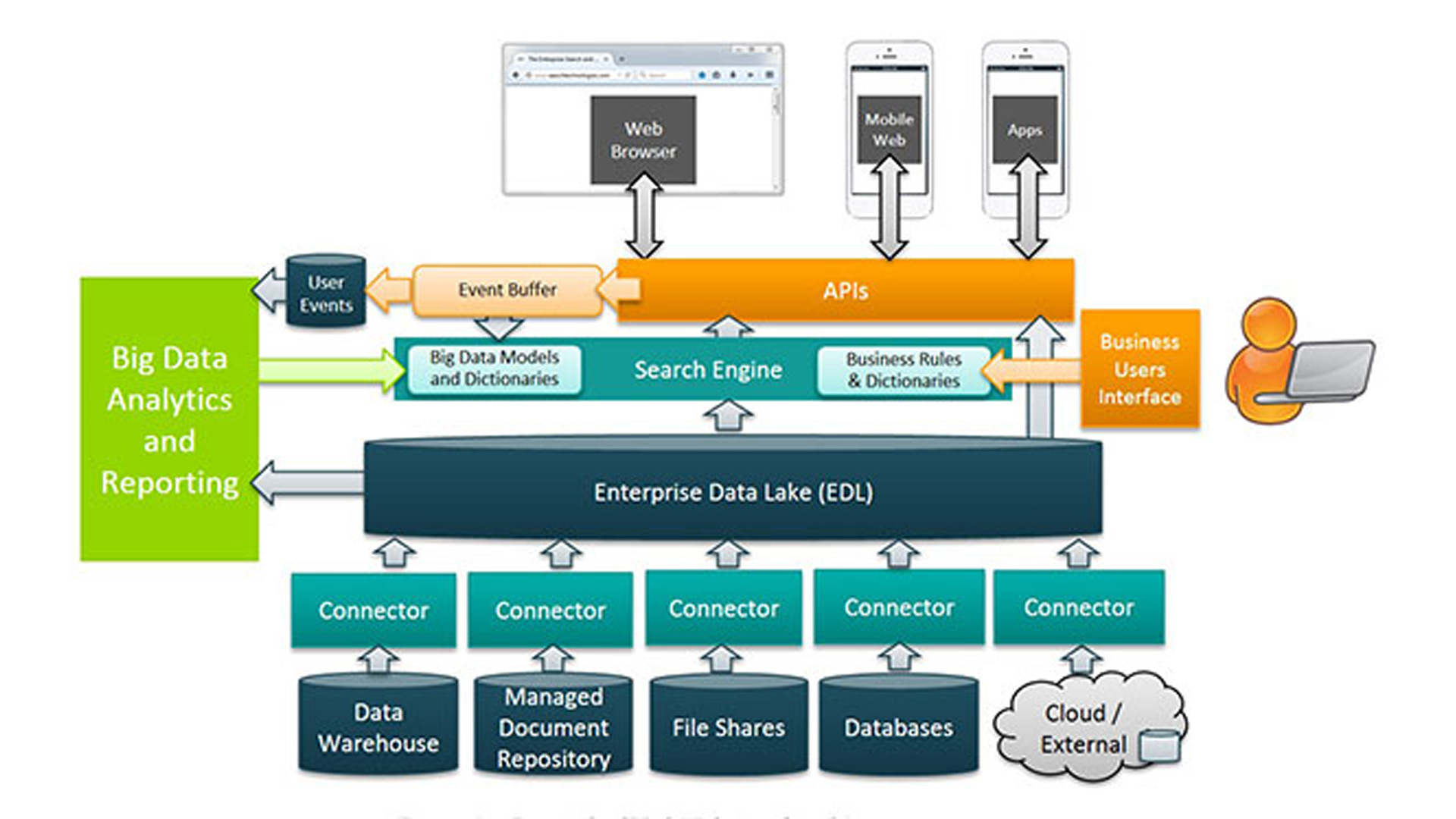
Fonte: Cloudera
Modelli di analytics
Gli strumenti di analytics vengono solitamente suddivisi in 4 macro categorie.
Descriptive Analytics
È l’insieme di strumenti orientati a descrivere la situazione attuale e passata dei processi aziendali e/o aree funzionali.
Predictive Analytics
Strumenti avanzati che effettuano l’analisi dei dati per rispondere a domande relative a cosa potrebbe accadere nel futuro; sono caratterizzati da tecniche matematiche quali regressione, forecasting, modelli predittivi, ecc;
Prescriptive Analytics
Tool avanzati che, insieme all’analisi dei dati, sono capaci di proporre al decision maker soluzioni operative/strategiche sulla base delle analisi svolte.
Automated Analytics
Strumenti in grado di implementare autonomamente l’azione proposta secondo il risultato delle analisi svolte.

Il mercato degli analytics in Italia
Per seguire il trend evolutivo del mondo analytics e comprenderne le dinamiche in Italia si fa riferimento alle analisi degli studiosi dell’Osservatorio su questo tema della School of Management del Politecnico di Milano.
I dati 2021
Mentre il Covid19 aveva rallentato significativamente il mercato dei big data analytics nel 2020, secondo i più recenti dati dell’Osservatorio Big Data & Business Analytics nel 2021 gli investimenti sono tornati a crescere in quest’ambito.
In totale, il mercato ha chiuso con un risultato di oltre 2 miliardi di euro. La componente software ha registrato la crescita più alta (+17%) accanto a quella dei servizi di consulenza e di customizzazione tecnologica.
Nell’analisi del mercato inerente al 2021, gli studiosi dell’Osservatorio si sono in particolar modo focalizzati sul rapporto Analytics e Pmi in Italia.
Nello specifico, gli analisti del Politecnico hanno rilevato che il 44% delle PMI nel 2021 ha investito in Analytics. Un altro 44% ha invece dichiarato di avere acquisito maggiore consapevolezza in merito al proprio bisogno di valorizzare le informazioni durante la pandemia. E, in effetti, almeno un’azienda su due ha cominciato a lavorare per integrare i dati interni.
Cosa è successo nel 2022
Secondo i dati dell’Osservatorio Big Data & Business Analytics 2022 , il mercato data management e analytics ha raggiunto i 2,41 miliardi di euro (+20% rispetto all’anno precedente).
L’incremento più consistente è stato realizzato dai prodotti software.
Nelle analisi emerge, inoltre, che cresce in modo rilevante la spesa destinata a servizi di Data Management & Analytics Public cloud.
Analytics: trend tecnologici
Dall’Osservatorio del Polimi alle società di ricerca internazionali come Gartner e Forrester, tutti hanno cercato di evidenziare trend consolidati o emergenti nell’ambito della data analytics. Eccone una sintesi.
Real time analytics
In sé, non è certo una novità. Il suo impulso innovativo sta nella possibilità di elaborare i dati in streaming, mentre continuano ad arrivare e non solo il loro deposito nei vari database o data lake.
Per esempio, l’analisi dei dati lungo il percorso verso il data lake, estraendo insight per compiere delle azioni, è alla base di alcune innovative applicazioni nell’ambito del marketing di prossimità, dell’identificazione delle frodi, della proactive maintenance e, in generale, in tutto il mondo dell’IoT. Tutto un mondo che dà vantaggio competitivo.
Machine learning e augmented analytics
Il volume dei dati da scegliere, raggruppare ed esaminare per trarne decisioni cresce a livelli tali da renderne in pratica impossibile l’uso per il business senza automatizzare i processi coinvolti. Nasce quindi una generazione di sistemi, indicata con l’espressione ‘augmented analytics’, che utilizza le piattaforme di machine learning e gli algoritmi di analisi contestualizzata agli eventi per alimentare nuovi servizi analitici. Servizi più capaci di approfondimento e spesso incorporati nelle applicazioni cui le analisi sono destinate.
Secondo Gartner si tratta di un trend che diverrà mainstream a breve. Automatizzare l’identificazione dei data set, dei pattern e delle ipotesi permette ai più capaci utenti delle applicazioni business (i ‘power user’) di fare da sé analisi predittive e prescrittive e agire di conseguenza utilizzando strumenti di self service data analytics.
Self service data analytics
La self-service data analytics, ossia la diffusione di strumenti che permettono all’utente di business di gestire in autonomia il processo d’interrogazione dei dati (dall’esplorazione all’analisi, fino alla visualizzazione degli insight), diventa driver tecnologico per abituare all’utilizzo dei dati un numero maggiore di utenti.
Gli analisti riconducono le soluzioni di Data Visualization e Reporting a 4 categorie principali.
- Report: cruscotti statici volti a visualizzare, in maniera sintetica analisi svolte da Data Scientist o Data Analyst.
- Dashboard periodiche Permettono visualizzazioni dinamiche in cui l’utente può interagire con i dati in maniera limitata, per esempio inserendo filtri o compiendo operazioni di drill-down.
- Dashboard aggiornate in tempo reale: cruscotti di visualizzazione dinamici in cui l’aggiornamento dei dati avviene in tempo reale.
- Strumenti di Visual Data Discovery. Essi abilitano, attraverso l’interazione visuale con i dati, l’esplorazione del data model e lo sviluppo di analisi complesse, quali analisi previsionali o di ottimizzazione.
Data as a service e data monetization
Oltre alla pura vendita del dato cosiddetto “grezzo”, le analisi che vengono effettuate sui dati raccolti danno vita a informazioni molto appetibili che possono essere vendute.
Si parla quindi di monetizzazione diretta o indiretta.
- Con la prima si identifica la valorizzazione del dato grezzo, così come viene raccolto. La vendita può avvenire a progetto (cioè con una singola transizione) o in sottoscrizione (nella vendita si definisce un intervallo di tempo entro il quale i dati vengono aggiornati dalla realtà venditrice).
- Più complessa la monetizzazione indiretta dove entrano fortemente in gioco le tecnologie di big data analytics. Qui quello che si vende è un servizio dove al dato viene associato uno strato di intelligenza che deriva dalla capacità di interpretazione dei dati. Entra dunque in gioco tutta l’expertise specifica dell’azienda.
Insight Platform
Secondo Forrester, le insight platform (piattaforme di conoscenza) stanno emergendo come evoluzione dei tool di big data management o analitici attraverso l’aggiunta di nuovi strumenti per sviluppare e testare insight, effettuare misure e monitoraggio da un’unica suite.
Si tratta di soluzioni che unificano tutto ciò che serve per creare tool che gestiscono e analizzano i dati. Esse integrano e provano gli insight per tradurli in azioni di business, quindi catturano i feedback per alimentare processi di miglioramento. Questo genere di soluzioni supera le difficoltà che oggi impediscono di tradurre la conoscenza in azioni, unificando la gestione dei dati per differenti servizi.
Non solo dati e metadati Hadoop, ma anche flussi e batch prodotti da altri framework di big data management. Poiché per ottenere insight utili servono più tipologie di analisi, è importante scegliere tra differenti tool di query, visualizzazione, modeling, eventualmente dotati di capacità real time.
Mettendo insieme data management, tool analitici e strumenti real time, le insight platform possono supportare logica di business in grado di automatizzare la gestione dati, le analisi e i modelli predittivi.
Nel system of insight dati, informazioni qualitative e quantitative, azioni mediate dal software operano all’interno di un ciclo chiuso.
Il circolo virtuoso collega applicazioni che:
- correlano i dati con gli insight,
- inseriscono gli insight nelle operazioni di business, traducendoli in azioni,
- collegano le azioni con i dati riportandoli al punto iniziale del processo di continua ottimizzazione.
In questi contesti le insight platform aiutano a creare applicazioni che fanno girare più velocemente i system of insight mettendo a disposizione quello che serve in termini di gestione dati, big data analytics, testing e tecnologia d’esecuzione.
Il metodo Agile nell’analisi dei dati
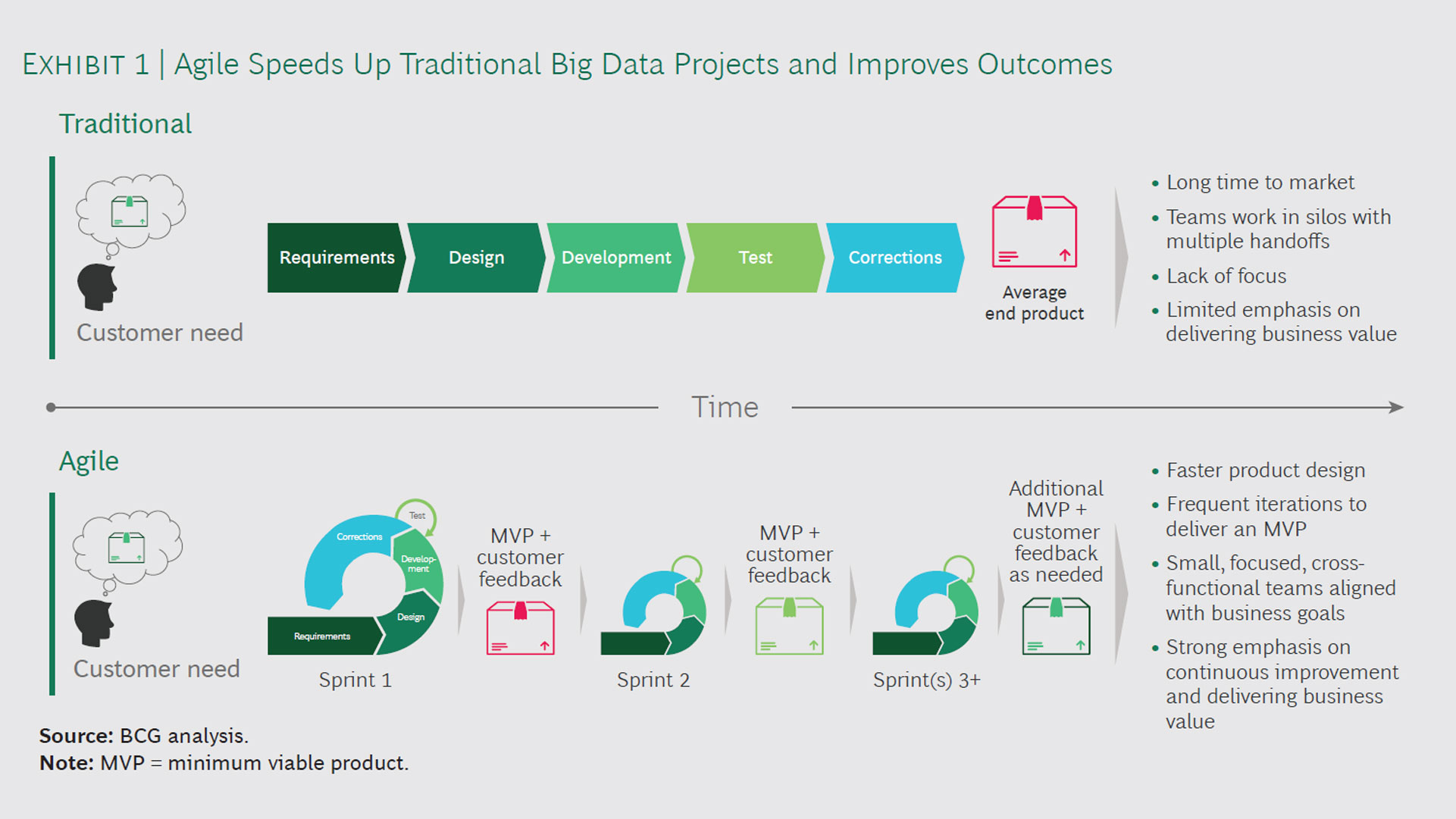
Secondo gli esperti di Boston Consulting Group (BCG) le cause di ritardo nei progetti aziendali di big data analytics hanno aspetti comuni. Data engineer, data scientist, esperti di modeling matematico, d’informatica e statistica hanno difficoltà a comprendere gli obiettivi del business e quindi a catturare elementi di valore nelle analisi.
Lo studio Using Agile to help fix Big Data’s big problem di BCG identifica il problema nel modo in cui si sviluppano le analisi. Esso applica i classici metodi a cascata del project management in cui ogni attività dipende dal completamento della precedente e dal tempo passato in riunione per l’allineamento delle attività. Lo Studio identifica la soluzione nell’adozione della metodologia Agile. Questa, grazie all’approccio iterativo ed empirico applicato a team interfunzionali, consente di arrivare rapidamente ad un Minimum Viable Product (MVP). Essa è la versione parziale, ma utilizzabile, del prodotto che, con i successivi feedback degli utenti e perfezionamenti, possa arrivare a soddisfare aspettative e obiettivi.
Le competenze necessarie per l’analytics
La carenza delle necessarie competenze, alquanto diffusa oggi in tutti i comparti dell’ICT, nell’ambito della Business Intelligence è legata in particolar modo a tre figure.
- Tecnologiche. Persone con skill di tipo matematico e algoritmico, finalizzati soprattutto al tema del machine learning e dell’Artificial Intelligence.
- Di connessione. Business translators, ovvero “traduttori” dei problemi che nascono nel contesto del business. E che sono in grado di trasformarli in task specifici da proporre alla data analysis.
- Business oriented. Il Business analyst, che individui i problemi all’interno delle varie parti dell’azienda e li porti all’attenzione delle persone preposte a risolverli.
È fondamentale che questi ruoli non si considerino a compartimenti stagni. Le competenze delle persone che li svolgono devono almeno in parte essere sovrapposte, in modo che possano dialogare efficacemente. Il presupposto deve essere una formazione comprensiva di vari elementi che possano dare una visione più ampia.
Gli ambiti applicativi: Web analytics e non solo
In una società data driven, gli ambiti applicativi della data analytics sono molteplici. Quelli di seguito raccolgono gli ambiti più rappresentativi.
Web analytics e Marketing optimization
Da processo creativo a processo altamente guidato dai dati. Il marketing è uno dei principali utilizzatori delle più avanzate tecnologie di analytics. Le organizzazioni di marketing utilizzano l’analisi per determinare i risultati delle campagne o degli sforzi e per guidare le decisioni per l’investimento e il targeting dei consumatori.
Gli studi demografici, la segmentazione della clientela, l’analisi congiunta e altre tecniche consentono ai professionisti del marketing di utilizzare grandi quantità di dati per capire e comunicare la strategia di marketing.
Uno strumento basilare per la marketing optimization è la Web Analytics che consente di raccogliere informazioni a livello di sessione su un sito Web. Grazie all’analisi di queste interazioni è possibile tracciare il referrer, cercare parole chiave, identificare l’indirizzo IP e tracciare le attività del visitatore.
Con queste informazioni, un marketer può migliorare le campagne di marketing, i contenuti creativi del sito Web e l’architettura delle informazioni. Le tecniche utilizzate frequentemente nel marketing includono la modellazione del marketing mix, le analisi dei prezzi e delle promozioni, l’ottimizzazione della forza vendita e l’analisi dei clienti.
Tramite i tool di web analytics si possono analizzare con un ottimo grado di dettaglio le proprie piattaforme digitali, effettuando benchmark con i dati provenienti dal mercato o con altre organizzazioni e siti del settore.
Google Analytics cos’è
Esistono diversi strumenti gratuiti e a pagamento per fare Web analytics. Tra questi, Google Analytics è il servizio gratuito offerto da Google che permette agli utenti di analizzare il comportamento dei visitatori di un sito Web. Fornisce le statistiche utili ai Web master e a coloro abbiano realizzato o vogliano fare campagne marketing su Internet. Attualmente è il tool più utilizzato per verificare la durata delle sessioni di visita ai siti, le pagine più viste, la provenienza della visita.
Google Analytics può essere integrato con Google Ads per analizzare le campagne online, monitorarne la qualità, la quantità di interazioni eccetera.
Google Analytics funziona aggiungendo il page tag. Si tratta del codice di tracciamento di Google (GATC, Google Analytics Tracking Code). Si tratta di un frammento di codice JavaScript che l’utente dello strumento pone in tutte le pagine del proprio dominio web. Tale codice, in contatto con il server di Google, permette di raccogliere i dati di navigazione degli utenti, che poi vengono analizzati e mostrati.
People Analytics
La people analytics è applicata specificatamente alle risorse umane. L’obiettivo è, attraverso l’analisi di dati comportamentali oltre a quelli classici relativi alla formazione, al cv eccetera. capire quali dipendenti assumere, quali ricompensare o promuovere, quali responsabilità assegnare…
L’analisi delle risorse umane sta diventando sempre più importante per capire quale tipo di profili comportamentali riuscirebbero e fallirebbero. Per esempio, un’analisi può scoprire che gli individui che si adattano a un determinato tipo di profilo sono quelli con maggiori probabilità di riuscire in un determinato ruolo, rendendoli i migliori dipendenti da assumere.
L’utilizzo della people analytics può avere uno spettro di azione molto ampio. Dall’analisi della produttività delle vendite a quella del turnover e della fidelizzazione dei dipendenti, da quella degli incidenti e delle frodi fino a quella che consente di capire quali sono i dipendenti capaci di determinare una maggiore fidelizzazione e soddisfazione dei clienti.
Portfolio analytics
Si tratta di un’applicazione molto comune per banche e agenzie di credito per bilanciare il rendimento del prestito con il rischio di default. I conti raccolti dalla banca possono differire in base allo status sociale del titolare, alla posizione geografica, al suo valore netto e ad altri fattori.
L’utilizzo della portfolio analytics consente di incrociare e analizzare tutti i dati. Combina l’analisi di serie temporali con molte altre questioni al fine di prendere decisioni su quando prestare denaro ai diversi segmenti di mutuatari o decisioni sul tasso di interesse.
Risk analytics
I modelli predittivi nel settore bancario sono sviluppati per garantire certezza ai punteggi di rischio per i singoli clienti. Si tratta quindi di una applicazione di analytics in parte sovrapponibile alla precedente anche se ha uno spettro di azione più ampio.
Si utilizza, per esempio, per analizzare se una transazione può essere fraudolenta utilizzando dati relativi alla cronologia delle transazioni del cliente.
Security analytics
Riguarda le tecniche di analytics per raccogliere e analizzare eventi di sicurezza per comprendere e analizzare gli eventi che presentano il maggior rischio. È una delle aree della data analytics di maggiore sviluppo.
Accanto ai rischi provocati da minacce malware o da vulnerabilità note aumentano quelli più sofisticati che richiedono la capacità di cogliere e analizzare “segnali deboli”. Fra questi i traffici di dati che apparentemente sembrano nella norma ma che si rivelano anomalie da cui possono derivare attacchi veri e propri.
I cybercrimali fanno ampio uso di analytics per lanciare i loro attacchi. Grazie al social engineering è molto più facile far cadere un utente nella trappola del phishing per permettere un attacco APT (Advanced Persistent Threat).
Obiettivo della Security Analytics è andare a caccia di minacce nascoste, tenere sotto controllo i traffici sulle reti e individuare i comportamenti anomali.
ITSM analytics
L’utilizzo della data analytics in ambito tecnologico, per modellare un ‘next generation’ IT Service Management, è un altro ambito di crescita. Gli strumenti di analytics consentono di estrarre informazioni per l’IT per intervenire in modo efficace. Vi sono alcuni interessanti ‘casi d’uso’ che producono valore sia sul piano IT sia nei confronti dell’utente.
- It Service Analytics. Strumenti con funzionalità di analisi real-time che forniscono la massima visibilità sulle relazioni tra le ‘transazioni’ di business e il comportamento delle applicazioni e delle infrastrutture a supporto. Il valore dell’IT sta proprio in questa capacità di analisi, il valore per l’utente di business (il principale cliente dell’IT) nel più efficace allineamento tra business e IT.
- Interaction Analytics, strumenti utili per il Service Desk. Gli strumenti analitici consentono di correlare i dati inerenti i servizi IT attraverso cui l’utente interagisce (profilo, accessi, utilizzo delle applicazioni, richieste). L’analisi di questi dati fornisce informazioni per migliorare il servizio di Help Desk e per automatizzare eventuali processi come gli interventi.
- Problem Analytics. In questo caso gli strumenti consentono di effettuare analisi correlate degli eventi in real-time. Automatizzano eventuali processi di intervento e abilitano un sistema di ‘supporto preventivo’. Si ha così miglior qualità del servizio, maggior capacità di risposta e riduzione dei tempi.
- Capacity Management. In questo caso gli strumenti di analytics consentono all’IT di modellare dinamicamente le risorse IT. Promuovono efficacia, in particolare, in funzione delle reali esigenze degli utenti e delle risorse IT necessarie ad ‘alimentare’ i servizi erogati.
Manutenzione preventiva
Dalla manutenzione predittiva dei macchinari all’interno delle fabbriche a quella degli oggetti, l’analytics combinata con IoT e edge computing rappresenta un altro ambito in espansione.
Software analytics
Si tratta dell’analisi dei sistemi software che tiene conto del codice sorgente, delle caratteristiche statiche e dinamiche e dei relativi processi di sviluppo. Questo serve per descrivere, monitorare, prevedere e migliorare l’efficienza e l’efficacia dell’ingegneria del software, in particolare durante lo sviluppo e la manutenzione.









