
- Il Machine Learning è un campo in rapida evoluzione con nuove applicazioni e tecnologie in continuo sviluppo.
- È importante utilizzare il Machine Learning in modo responsabile e consapevole dei potenziali rischi etici.
- Il Machine Learning non sostituisce l’intelligenza umana, ma la integra e la potenzia.
Oggi, il machine learning è considerato la concretizzazione più matura dell’intelligenza artificiale (IA) o artificial intelligence (AI). Attualmente un pc, uno smartphone o un qualsiasi dispositivo digitale (standalone o, meglio ancora, collegato al cloud) si può comportare in maniera “intelligente” come o più di un essere umano. Solitamente questo avviene perché utilizza qualche applicazione di machine learning (ML). E ormai sono miliardi i dispositivi e i software di questo tipo diffusi in tutto il mondo.
Indice degli argomenti
Cos’è il machine learning, il ruolo dell’intelligenza artificiale
La madre di tutti gli algoritmi di intelligenza artificiale è il machine learning ossia l’apprendimento automatico. Più nello specifico, il significato di machine learning si esprime nella capacità di imparare ed eseguire compiti da parte della macchina sulla base di algoritmi che apprendono dai dati in modo iterativo.
Un’applicazione ML-based difficilmente può sostituire una convenzionale, in cui le regole per ottenere specifici obiettivi sono già state fornite nel codice. Un software basato sull’apprendimento automatico, infatti, a differenza di uno tradizionale impara come risolvere i problemi effettuando esperienza direttamente con i dati.
Come funziona l’apprendimento delle macchine
Affinché una macchina sia in grado generare al proprio interno le regole per elaborare i dati in ingresso (spazio di input) sono necessari algoritmi appositi di ML (scritti con linguaggi comuni come C++, Pyton o Java), moltissimi dati di esempio, capacità computazionale e memoria.
Funzionamento di un algoritmo di machine learning
I modi di imparare degli esseri viventi sono diversi, in base al tipo di problemi da risolvere. Così gli algoritmi di machine learning prevedono differenze a seconda del tipo di apprendimento che devono consentire. Ricordiamo che un algoritmo è una serie di operazioni semplici, diverse fra loro, che, eseguite in un ordine prestabilito, permettono di giungere ad un risultato atteso.
3 tipi di Machine learning
Tre sono i più comuni metodi di learning per i quali gli algoritmi devono essere concepiti: apprendimento supervisionato, apprendimento non supervisionato (o self supervisionato) e apprendimento con rinforzo. In alcuni casi un’applicazione ML può prevedere l’uso di più tipi di learning.
Apprendimento supervisionato (supervised learning)
È quello più comunemente utilizzato. Il programma viene addestrato su coppie di dataset input/output predefinite dai trainer in cui le risposte giuste sono già state identificate o etichettate (labeled). Al modello viene chiesto di elaborare gli esempi forniti in ingresso fino ad ottenere risultati uguali a quelli presentati in uscita. Ogni volta che l’applicazione fornisce un risultato diverso da quello atteso, un meccanismo di retroazione innesca un processo di ottimizzazione dell’algoritmo finché, alla fine dell’addestramento, l’applicazione sarà in grado di fornire risposte giuste. O altamente probabili, nel caso in cui il modello riconosce pattern non identici da simili a quelli su cui ha fatto esperienza.
Apprendimento non supervisionato (unsupervised learning)
A differenza di quello precedente, in questo caso all’applicazione sono forniti solo esempi in ingresso con dati né labeled né classificati, ossia in inseriti in categorie in base a certe valutazioni (per esempio posta normale o spam). Il modello deve trovare le relazioni non lineari all’interno dei dati e capire quali consentono di raggiungere i risultati migliori rispetto agli obiettivi del modello. Ad esempio la quotazione di un appartamento o il valore di un’azione di borsa in un certo momento.
Apprendimento con rinforzo (reinforcement learning)
Questo tipo di learning è utilizzato soprattutto in applicazioni che devono interagire con contesti altamente dinamici e incerti. Come nell’apprendimento supervisionato, al modello sono posti degli obiettivi da raggiungere, un sistema di ricompense (rewards) o penalità (penalties) ma non sono forniti suggerimenti sugli oggetti che può incontrare o sulle regole del gioco adottate nell’ambiente. Il modello impara come effettuare le decisioni in modo iterativo, attraverso tentativi con quello che si trova a disposizione, i reward e le penalty.
Le metodologie algoritmiche usate nel machine learning
Queste tecniche si sostanziano con l’applicazione di diverse tipologie di algoritmi. Di seguito riportiamo alcune delle tecniche e metodologie algoritmiche più importanti e utilizzate nel machine learning.
Alberi di decisione
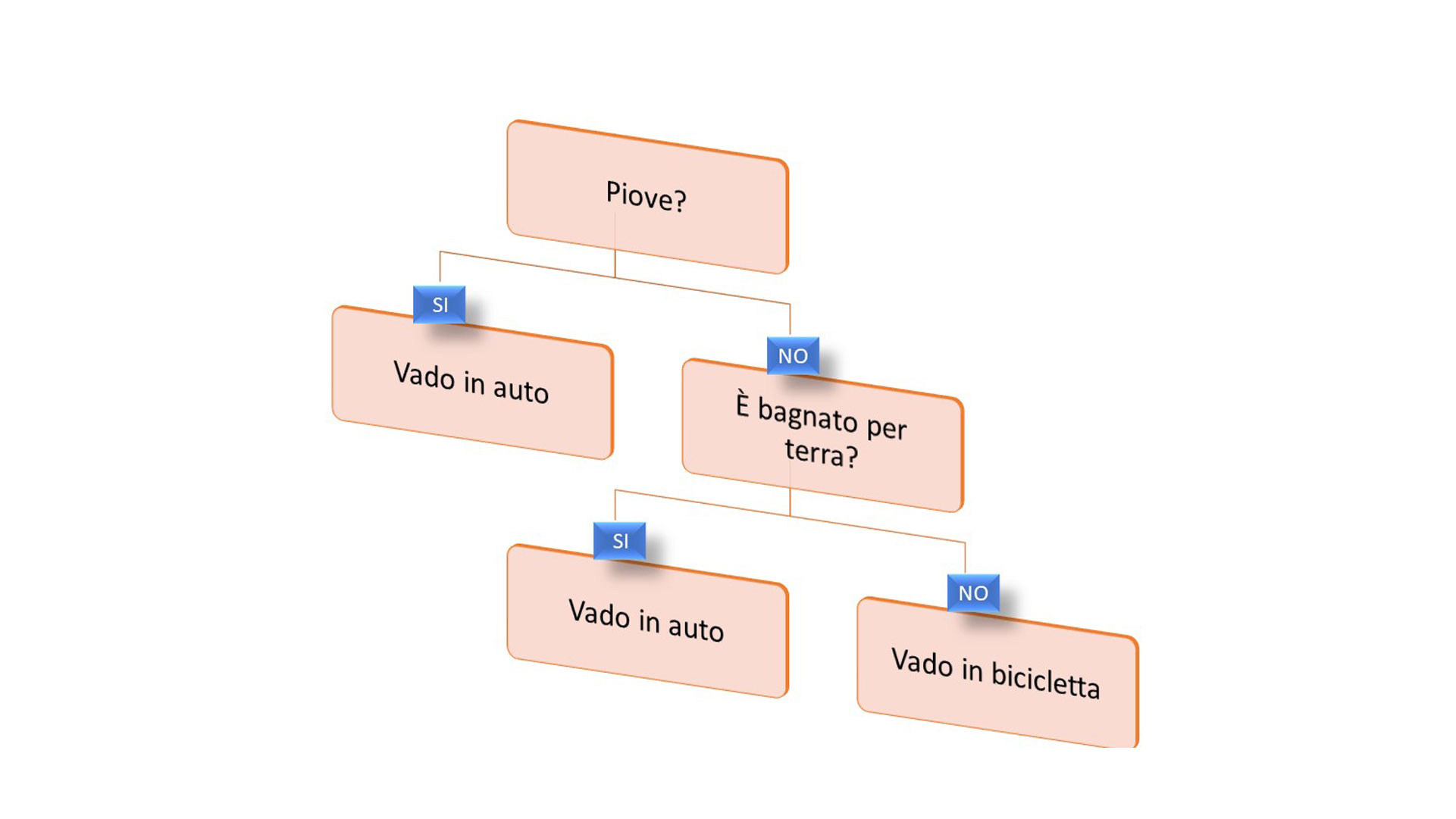
Utilizzati in particolar modo nei processi di apprendimento induttivo basati sull’osservazione dell’ambiente circostante da cui derivano le variabili di input (attributi). Il processo decisionale è rappresentato da un albero logico rovesciato dove ogni nodo è una funzione condizionale (figura 1). Il processo è una sequenza di test che inizia dal nodo radice e procede verso il basso scegliendo una direzione piuttosto di un’altra sulla base dei valori rilevati. La decisione finale si trova nei nodi foglia terminali. Tra i vantaggi vi è la semplicità e la possibilità di verificare attraverso quale processo la macchina è giunta alla decisione. Lo svantaggio è che si tratta di una tecnica poco adatta a problemi complessi.
Classificatori bayesiani
Si basa sull’applicazione del teorema di Bayes (dal nome del matematico britannico che, nel XVIII secolo, ha sviluppato un nuovo approccio alla statistica). Esso viene impiegato per calcolare la probabilità di una causa che ha scatenato l’evento verificato (figura 2). Per esempio: appurato che l’elevata presenza di colesterolo nel sangue può essere causa di trombosi, rilevato un determinato valore di colesterolo, qual è la probabilità che il paziente sia colpito da trombosi? I classificatori bayesani hanno differenti gradi di complessità.
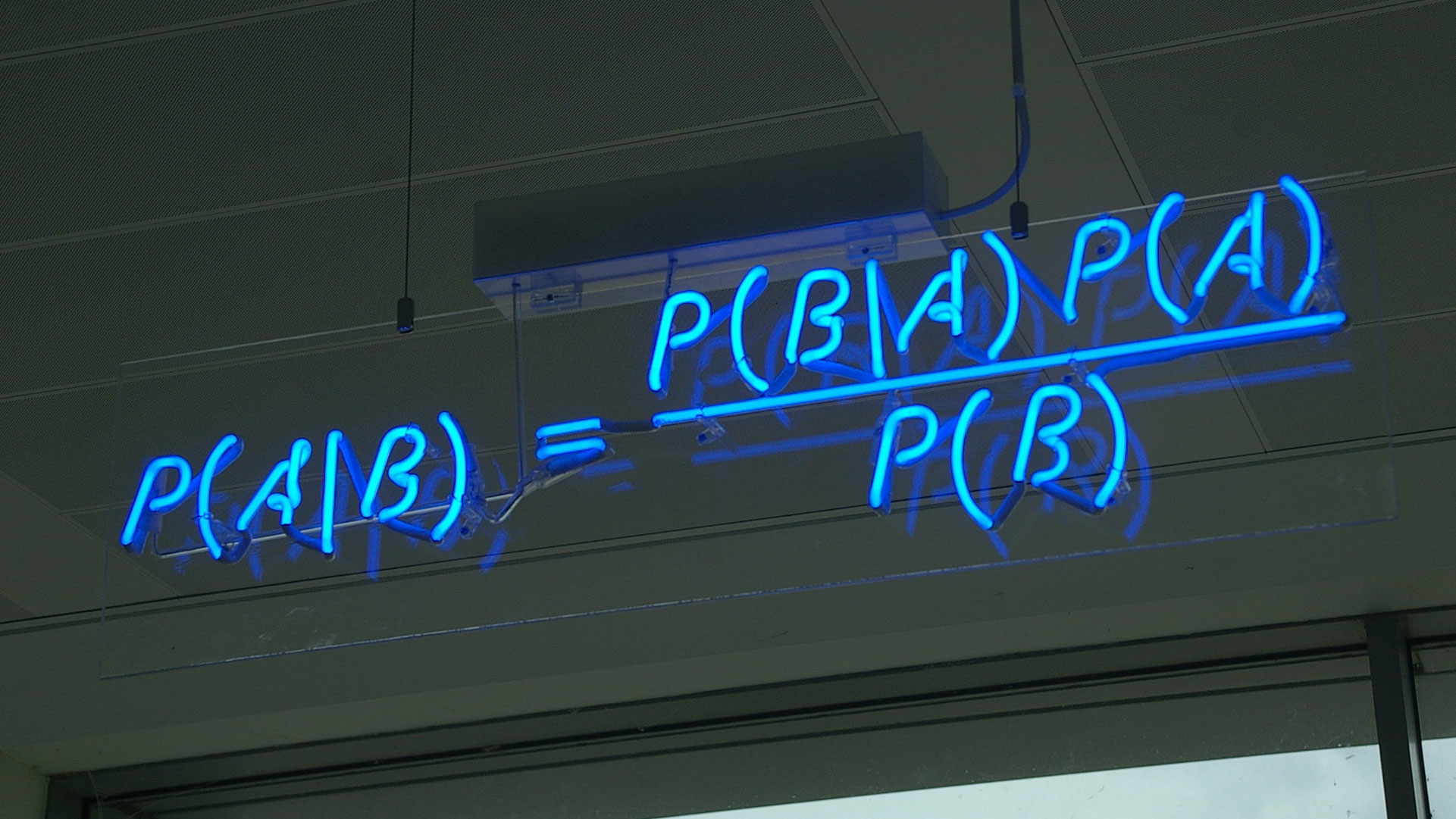
Macchine a vettori di supporto (SVM, Support Vector Machines)
Sono metodologie di apprendimento supervisionato per la regressione e la classificazione di pattern. Appartengono alla famiglia dei classificatori a massimo margine (classificatori lineari che contemporaneamente al tempo minimizzano l’errore empirico di classificazione e massimizzano il margine geometrico, ossia la distanza tra un certo punto x e l’iperpiano che, a sua volta, è un sottospazio lineare di dimensione inferiore di uno (n − 1) rispetto allo spazio in cui è contenuto (n)).
In queste macchine, gli algoritmi di learning sono disaccoppiati dal dominio di applicazione che viene codificato nella progettazione della funzione kernel. Questa funzione mappa i dati sulla base di caratteristiche multidimensionali e consente di creare un modello approssimativo del mondo reale (3D) partendo da dati bidimensionali (2D).
L’applicazione più comune delle SVM è la visione artificiale. Nell’immagine di un gruppo dove sono presenti uomini e donne (sulla base della funzione kernel che definisce il sesso considerando vari parametri) la SVM riesce a separare gli uni dalle altre. Un’altra cosa che è importante sapere è che questi classificatori vengono contrapposti alle tecniche classiche di addestramento delle reti neurali artificiali.
Apprendimento ensamble
È la combinazione di diversi metodi (a partire dai classificatori bayesani) per ottenere una migliore prestazione predittiva di quanto non facciano i singoli metodi che combina. L’apprendimento ensamble si divide in 3 tecniche fondamentali (bagging, boosting e stacking).
Analisi delle componenti principali (in inglese PCA – Principal Component Analysis)
È una tecnica di semplificazione dei dati. Il suo scopo è ridurre il numero di variabili che descrivono un insieme di dati a un numero minore di variabili latenti, limitando il più possibile la perdita di informazioni.
Esempi di Machine Learning e applicazioni dell’apprendimento automatico
Un’applicazione ML dipende dai suoi sviluppatori e dai data scientist, che a loro volta – solitamente – rispondono alle richieste di qualcuno che ha obiettivi in qualche settore specifico. Ecco alcuni esempi di ambiti applicativi.
Marketing
Le applicazioni basate sull’apprendimento automatico dai dati sono in grado di ricostruire al proprio interno modelli della realtà e su di esse effettuare valutazioni e previsioni su cui prendere decisioni. Per questo motivo, molte aziende che operano in contesti competitivi sfruttano una o più applicazioni differenti di AI per perfezionare o personalizzare i loro prodotti o servizi. E crearne di nuovi in modo rapido.
Gestione patrimoniale, medicina e filiere
Spesso i fattori di cui tenere conto per stabilire il valore di beni mobiliari o immobiliari, fare una diagnosi medica o compiere scelte nella gestione di una filiera di business sono moltissimi e non tutti conosciuti a priori. Per questo motivo, nella realtà, questi operatori si devono basare, oltre che su competenze specifiche, sull’intuito, l’esperienza e la fortuna. Le soluzioni ML, a differenza di quelle tradizionali, estrapolano nessi e leggi, anche di tipo probabilistico. E si basano su una conoscenza creata con l’addestramento su migliaia e migliaia di esempi. E questo le aiuta a fornire suggerimenti utili, anche se non sempre se ne comprende la ratio.
Gestione dei data center
I data center sono diventati enormi e complessi centri nevralgici nell’era digitale. Per gestire in modo più efficiente, sicuro e sostenibile uno o una rete di data center oltre ai più comuni parametri utilizzati (temperatura, umidità, consumi etc.) si aggiungono altri indicatori non facilmente o immediatamente riconoscibili. Molti vendor DCIM (Data Center Infrastructure Management) stanno aggiungendo alle loro soluzioni strati di ML che analizzato i dati grezzi raccolti da sensori o inviati come log, e segnalano tipi di dati o pattern nuovi da inserire eventualmente nelle applicazioni di analitica avanzata.
I vantaggi dell’apprendimento automatico
Il machine learning è da utilizzare quando gli scenari in ingresso sono così complessi e variabili che anche l’essere umano fatica a riconoscere e misurare tutto. Tuttavia è utopistico aspettarci – come del resto avviene con gli esseri umani – che le applicazioni di ML forniscano sempre risultati esatti. Per contro, i sistemi ML-based (o in generale AI-based) possono mostrare performance analoghe a quando gli umani, nel prendere una decisione, non si basano solo su logica e calcoli, ma anche sull’intuizione e sull’esperienza pregressa.
Siccome le aziende operano in scenari di business sempre più complessi e in cui il time-to-market è sempre più importante, in molti casi (ma non tutti) le versatili applicazioni ML permettono di evitare lunghi e costosi progetti di sviluppo software tradizionale ad hoc.
Differenze tra machine learning e deep learning
In teoria, il deep learning (apprendimento profondo) è un sottoinsieme del machine learning. In realtà, ML e DL oggi possono essere considerate due categorie distinte. Il ML utilizza un’architettura software tradizionale, mentre il DL si basa su reti neurali artificiali (RNA) che si ispirano al cervello. Nel ML i problemi di grandi dimensioni sono suddivisi in blocchi di problemi più piccoli. Ognuno viene risolto separatamente. E si ricompongono tutte le soluzioni. Il processo è iterativo.
Il DL adotta invece un approccio più end-to-end e stratificato. Nel ML è più importante che tutti gli algoritmi siano in grado di riconoscere i dati presenti nei dataset. In caso contrario viene richiamato in causa i data scientist. Nel DL, quasi sempre le decisioni sui dati sconosciuti vengono prese automaticamente analizzando altri dati. Infine, il ML può girare più facilmente con sistemi di computing tradizionali e in locale (o all’edge). Il DL richiede grande capacità computazionale (fornita quasi sempre da GPU), molta capacità di memoria e lunghi tempi di addestramento.











Partecipa alla community