
MONACO – Nei giorni 5 e 6 aprile scorsi, la moderna struttura del Centro Congressi Internazionale della capitale bavarese è stata monopolizzata dal primo DataWorks Summit, evento che rappresenta un’importante e per certi versi esclusiva occasione
 | Di questo servizio fa parte anche il seguente articolo: |
 | IL SUMMIT – Dataworks Summit: nuove analytics per accelerare l’impresa digitale |
di incontro tra molte delle realtà che, a vario titolo, fanno parte della comunità Hadoop in Europa. In effetti, il meeting bavarese non è stato una ‘prima’ assoluta, ma il prosieguo, con un diverso nome, dei precedenti Hadoop Summit, che, inaugurati nel 2014, erano quindi giunti l’anno scorso alla terza edizione. Un cambiamento reso necessario dallo sviluppo di una soluzione, Hadoop appunto, che nata più di dieci anni fa come un progetto della Apache Foundation inteso a potenziare l’efficienza dei motori di ricerca è in breve diventata la piattaforma software di elezione per lo storage e l’elaborazione di grandi volumi di dati eterogenei e alla quale, quindi, il ‘brand’ Hadoop incomincia a stare stretto.

Shaun Connolly, Chief Strategy Officer, Hortonworks
Il disegno di Hadoop si ispira dichiaratamente al file system distribuito e al software per il governo del calcolo su nodi clusterizzati (MapReduce) sviluppati a suo tempo da Google per il proprio motore di ricerca, ed entrambi proprietari del colosso di Mountain View. Non stupisce quindi che il maggior impulso e contributo al progetto Apache siano giunti da Yahoo!, che di Hadoop è il primo e principale utilizzatore, né che tra i primi grandi utenti figurino nomi come AOL, Ebay, Spotify, Facebook, Twitter e Linkedin.
Nel giugno 2011, ben prima della comparsa ufficiale di Hadoop, la cui release 1.0 viene resa disponibile nel novembre 2012, in seguito ad un’iniziativa che di fatto rappresenta uno spin-off della stessa Yahoo!, nasce Hortonworks. Nascita la cui genesi (vedi box) spiega lo stretto rapporto, quasi di ‘primogenitura’, che lega l’Hadoop Summit – DataWorks Summit (che nell’agenda ufficiale figura infatti “Presented by Hortonworks and Yahoo!”) e tutto ciò che della comunità open source rappresenta a una software house che opera secondo il consueto modello delle distribuzioni di software o.s. integrate e ottimizzate in piattaforme di soluzioni e servizi concepiti e venduti per l’uso in ambienti enterprise.
Indice degli argomenti
Dall’universo dati nuovi livelli di analytics

Rajinish Verma, President e Chief Operating Officer, Hortonworks
Dopo questa necessaria premessa e lasciando le osservazioni sui più notevoli aspetti dell’evento ad altri articoli passiamo al vero nocciolo del Summit, cioè ai diversi ‘keynote’ nei quali Hortonworks ha illustrato ai suoi partner e agli altri convenuti, sviluppatori e utenti Hadoop, la propria visione e strategia.
Shaun Connolly, Chief Strategy Officer, ha aperto gli interventi con una presentazione nella quale ha illustrato, con comprensibile orgoglio, i primati della società, sottolineando sia i dati finanziari e la crescita del business (vedi box), sia il fatto d’avere per prima realizzato un’architettura d’interconnessione dati che copre sia l’on-premises che il cloud. Sullo sviluppo del business la strategia di Connolly punta sull’internazionalizzazione. “Le revenue al di fuori degli Usa hanno contribuito l’anno scorso solo al 24% del totale, ma sono cresciute più del 120%. Per ampliare il mercato internazionale intendiamo sia creare filiali locali sia rafforzare il canale, lavorando con system integrator, Isv e Oem”. A tal fine si è anche data una nuova leadership, nominando a febbraio Rajinish Verma President e Chief Operating Officer.
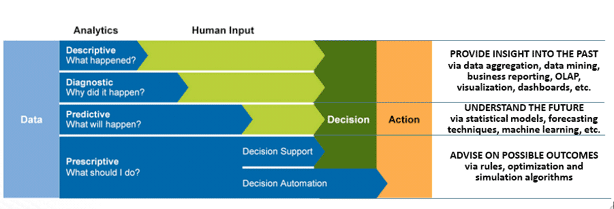
Quanto alla ‘vision’, questa è tanto semplice quanto ambiziosa. “Vogliamo – ha detto Connolly – realizzare un’offerta capace di gestire l’intero mondo dei dati per mezzo di un’architettura che interconnetta Big Data, IoT e Cloud Computing”. In altri termini, l’obiettivo è fornire soluzioni in grado di operare su quelle attività dove le analisi sui dati “in store” e su quelli streaming vanno a sommarsi per fornire un nuovo livello d’informazione. Il concetto è stato ripreso e dettagliato da Rajinish Verma, che ha mostrato, con esempi che vanno dal manufacturing alla distribuzione, come: “Le opportunità che derivano dalla capacità d’integrare e fondere la gestione e analisi dei dati in riposo e in movimento sono già oggi numerose e lo saranno sempre più man mano che le imprese ne colgono i vantaggi”. Si prefigura uno sviluppo delle analytics dove al crescere del volume dei dati e della complessità di elaborazione il rapporto tra gli algoritmi e l’intervento umano si sposta a favore dei primi fino a giungere all’automazione delle decisioni (vedi figura 1).

Figura 2 -Il modello di Actionable Intelligence
In questo quadro di “actionable intelligence”, come è stata definita, il supporto dei servizi di data processing sul cloud diventa importante sia per i noti vantaggi operativi ed economici sia per la sicurezza, che la Data Cloud Architecture di Hortonworks assicura con policy diverse (permessi e proibizioni, location e data expiry) combinabili fra loro a seconda dei casi.

Scott Gnau, CTO, Hortonworks
È toccato infine al CTO Scott Gnau, sino a due anni fa a capo dei Teradata Labs, parlare delle tecnologie dell’offerta oggi più ‘calda’ per la strategia della società, cioè l’analytics in data streaming della Hortonworks DataFlow, che sfrutta Apache NiFi per l’acquisizione e la gestione dei dati e Apache Storm e Kafka per l’analisi real-time, e soprattutto presentare la versione 2.6 della Hortonworks Data Platform, vera novità del Summit. Senza entrare in dettaglio, dato che il prodotto è già disponibile e scaricabile online, con tutte le specifiche necessarie, i plus che interessano l’impresa utente e le relative tecnologie o.s. sono quattro: la velocizzazione delle operazioni (Apache Ambari 2.5); la maggiore scalabilità (Apache Spark 2.1 e Zeppelin 0.7); l’apertura alle applicazioni real-time (con il supporto di HBase/Phoenix e Druid) e soprattutto la nuova potenza delle query, che grazie alla fusione in Apache Hive dei requisiti ACID (Atomicità, Consistenza, Isolamento e Durata delle transazioni) e delle tecnologie LLAP (Low latency Analytical Processing) offre ora un incremento prestazionale di un ordine di grandezza, con query interattive eseguibili in pochi secondi.
Una crescita boom nel nome dell’open sourceHortonworks viene fondata nel giugno 2011 come software house indipendente con un primo finanziamento di 23 milioni di dollari forniti da Yahoo! (dalla quale proviene anche il nucleo dello staff tecnico e dirigente nonché il suo primo Ceo) e da Benchmark, società di venture capital che ha già al suo attivo ‘colpi’ come eBay, Twitter, Uber e Dropbox). Dopo soli quattro mesi annuncia un accordo strategico con Microsoft per la distribuzione di Hadoop (che non è ancora reso disponibile come software open source) per Windows Server su Ms Azure. La versione per Windows sarà pronta in beta release più di un anno dopo, ma la fiducia nella neonata società è tale che a un mese dall’annuncio raccoglie altri 25 milioni dalla Index Venture. Nel febbraio 2012 viene stretta una seconda partnership strategica con Teradata, che sei mesi dopo si concretizza in un’appliance per le big data analytics, e nel 2013 la distribuzione Hortonworks entra nel portafoglio dell’offerta Hadoop-based di Sap. Questi risultati e il fatto che nel frattempo il suo Hadoop si stia sviluppando nella Hortonworks Data Platform (HDP), piattaforma dati pensata per l’impresa, attirano nuovi investitori e in breve nel capitale della software house affluiscono altri 150 milioni (100 dei quali da BlackRock), che nel 2014 la portano ad essere quotata al Nasdaq e ad acquisire XA Secure, società specialista in sicurezza le cui soluzioni a livello ‘enterprise’ (controlli centrali, funzioni di auditing e compliance…) aggiungono un importante tassello alla sua offerta. Nel 2015, dopo l’acquisizione di Onyara, software house promotrice del progetto Apache NiFi, viene lanciata la Hortonworks DataFlow (HDF), piattaforma per la raccolta e l’analisi in real-time dei data-stream generati dall’universo dei sensori IoT. Nel biennio 2015-16, l’offerta cloud si definisce nell’HDInsight, che porta su Ms Azure tutti i componenti-chiave della HDP (cioè Hadoop, Spark, HBase, Storm, Hive, Kafka e Ms R Server) e soprattutto, nel novembre scorso, aggiunge alla disponibilità sul cloud Microsoft anche quella su Amazon WS. Oggi Hortonworks ha 1.050 dipendenti, serve più di mille clienti in 60 Paesi e ha chiuso l’esercizio 2016 con un incasso record di 184,5 milioni di dollari, con una crescita del 74% anno su anno, specie negli abbonamenti (oggi oltre il 68% delle revenue) che le ha permesso di andare in break-even Ebtda, cioè in base al margine operativo lordo. |









